Web上的信息具有异质性和动态性,由于受时间和存储、带宽的限制,不可能把所有的网页都搜集起来,一个好的搜集策略是有限搜集重要的网页。对于网页的重要程度的评定,要依据搜集信息所针对的不同应用而定,从而信息的搜集可以采取不同的策略。而目前这个问题尚无定论,一般按照如下几种指标来共同确定网页的重要性:
1)网页的入度大,也就是被引用的次数多;
2)该网页的父网页入度大;
3)网页有多个镜像ip;
4)网页的目录深度小,用户比较容易达到;
5)网页内容有较高的信息熵;
6)网页的更新频度比较高;
搜索引擎开始工作的时候,以上的参数都无法知道,这是一个渐进的优化过程。重要的页面不一定就是优先抓取的对象,还需要综合考虑其他的影响性能的参数,逐步调优。
Tuesday, January 16, 2007
第一章 1.2 声明 Declaration
本文的主旨是提供学习的基本导向,并对一些重要的技术细节进行剖析,舍去很多拖沓的描述,力图给读者深度和广度全面的理解web搜索的基本机制。
/**********本文并不申明为权威工程应用指南************/
/**********本文并不申明为权威工程应用指南************/
Thursday, January 11, 2007
第一章 1.1 兴趣的开始 Game Is Now Beginning
Web上数十亿张网页,认真地在网络上乱逛发现最大的需求是:哪里有好东西?我们能用它们来做什么?每个人对他们自己认为的有效信息有不同的看法,且大多数人当他们一旦找到好东西的时候,总是有一些创造性的电子。在某些web的角落,鼓励用有趣的方式来重新组织和运用这些资讯,而这些不平凡的资讯组合不容怀疑地向前流动,他们相信信息时代的到临。让我们开始漫长的学习历程吧!
Wednesday, January 10, 2007
第四章 索引 Full Text Indexing
在学习搜索引擎技术之前最好有一定的知识储备,Modern Information Retrieval 是本经典IR的教材,本文默认读者已经具有相应的基础。
数据需要分不同的类型进行相应处理,一般的网页内容文本大致可以分为四部分:
Keyword: 不做分析,逐字/词建索引并存储.例如URL,文件系统路径,日期,人名,社会保险帐号,电话号码等。举了本地搜索的例子,可以把系统路径名作为关键词.
UnIndexed: 不做分析也不做索引,但是值存储在索引中。这种一般是提供搜索结果的可显示内容。这些内容我们通常不需要去搜索(URL或者是数据库的主值),只是在索引中存储原始的值。于是这里不适合存储大量的信息。
UnStored: 和UnIndexed相反,对这类field做分析和索引,但是不在索引中存储。通常是不需要在其原始的形式中检索信息,比如web页面的body部分,或者一些不大重要的文本。
Text: 分析,索引,存储索引。意味着将对这部分进行索引。
当然不局限于这几种,实际应用中可以扩展设计出更多的数据类别。设计的原则可以归结为:经常需要被检索的内容或者说网页的实质内容要建立相应的索引(和词典的功能类似),提供有效的信息组织形式并减少冗余。
索引和查询的底层实现是搜索引擎的核心:
1)尽可能对字段进行索引来提高查询速度,但过多的索引会对索引表表的更新操作变慢,而对结果过多的排序条件,实际上往往也是性能的杀手之一。
2)索引器的merge_factor提供了归并几个索引的功能,参数的合理设置直接影响了索引器的性能。
3)20%/80%原则:查的结果多并不等于质量好,尤其对于返回结果集很大,如何优化这头几十条结果的质量往往才是最重要的。
4)尽可能缩小减缩的结果集相对于单个应用来说,因为即使对于大型分布式文件系统,对结果集的随机访问也是一个非常消耗资源的操作。
数据需要分不同的类型进行相应处理,一般的网页内容文本大致可以分为四部分:
Keyword: 不做分析,逐字/词建索引并存储.例如URL,文件系统路径,日期,人名,社会保险帐号,电话号码等。举了本地搜索的例子,可以把系统路径名作为关键词.
UnIndexed: 不做分析也不做索引,但是值存储在索引中。这种一般是提供搜索结果的可显示内容。这些内容我们通常不需要去搜索(URL或者是数据库的主值),只是在索引中存储原始的值。于是这里不适合存储大量的信息。
UnStored: 和UnIndexed相反,对这类field做分析和索引,但是不在索引中存储。通常是不需要在其原始的形式中检索信息,比如web页面的body部分,或者一些不大重要的文本。
Text: 分析,索引,存储索引。意味着将对这部分进行索引。
当然不局限于这几种,实际应用中可以扩展设计出更多的数据类别。设计的原则可以归结为:经常需要被检索的内容或者说网页的实质内容要建立相应的索引(和词典的功能类似),提供有效的信息组织形式并减少冗余。
索引和查询的底层实现是搜索引擎的核心:
1)尽可能对字段进行索引来提高查询速度,但过多的索引会对索引表表的更新操作变慢,而对结果过多的排序条件,实际上往往也是性能的杀手之一。
2)索引器的merge_factor提供了归并几个索引的功能,参数的合理设置直接影响了索引器的性能。
3)20%/80%原则:查的结果多并不等于质量好,尤其对于返回结果集很大,如何优化这头几十条结果的质量往往才是最重要的。
4)尽可能缩小减缩的结果集相对于单个应用来说,因为即使对于大型分布式文件系统,对结果集的随机访问也是一个非常消耗资源的操作。
第三章 并行分布式文件系统 Parallel Distributed File System
搜索的引擎的存储规模至少都是TB级别,如何有效地管理和组织这些资源呢?并且在极短的时间内得出结果?MapReduce: Simplified Data Processing on Large Clusters 给出了很好的分析。
分布式文件系统的实施必须实现两种临界资源的接口,一个是文件名到命名空间的映射表,另外一个是块表对应到结点机器列表。其中命名空间表示的是文件名到一组机器的映射,具体hash函数可能需要看命名空间的规模,其实就是一个Map过程;其中块表到机器列表的对应,实际是一个Reduce过程,分块存储到控制下的机器群(inodes),换句化说是slave-master的架构,通信的方式越底层的协议执行起来效率越高。具体实现可以参照hadoop。
当然需要考虑的还有很多的细节问题,比如inode机器的turn up 和 turn down,实时地识别这些出现的新机器,关掉的机器也自动地从列表中删除;备份数据个数的选择,备份之间的负载平衡;inode的配置文件的维护;对于终端的用户来说,文件系统虚拟化;
分布式文件系统的实施必须实现两种临界资源的接口,一个是文件名到命名空间的映射表,另外一个是块表对应到结点机器列表。其中命名空间表示的是文件名到一组机器的映射,具体hash函数可能需要看命名空间的规模,其实就是一个Map过程;其中块表到机器列表的对应,实际是一个Reduce过程,分块存储到控制下的机器群(inodes),换句化说是slave-master的架构,通信的方式越底层的协议执行起来效率越高。具体实现可以参照hadoop。
当然需要考虑的还有很多的细节问题,比如inode机器的turn up 和 turn down,实时地识别这些出现的新机器,关掉的机器也自动地从列表中删除;备份数据个数的选择,备份之间的负载平衡;inode的配置文件的维护;对于终端的用户来说,文件系统虚拟化;
第二章 爬虫 Spider
简单地说,爬虫负责按照url列表爬取网页的内容,实际中需要针对不同的协议设计爬虫程序并优化。写一个优秀的爬虫不是件容易的事情,仅列举部分设计必须考虑到的问题。
1.严格按照robots.txt 来爬取内容,优先按照sitemap来抓取。
2.控制抓取的深度,量力而行。这个和人吃饭一次吃多少的道理是一样的。
3.网络上动态网页数量巨大,而爬虫一般是多线程的,如果爬虫对一个domain爬取的频率过高可能导致服务器无法相应;如何克服,如何让爬虫相对比较智能地平衡网络负载,运算负载,存储负载?
4.不要试图去解析页面中的脚本代码,可能是恶意的程序,也可能是有bug的代码,在本地运行会将计算的消耗提升到不可预期的程度。
5.如何节约带宽,需要检测到网页的更新,请求head信息以获取更新状态。
6.如何把计算网页权重结合到爬虫程序中?因为爬取的过程中还是相当的cpu资源没有被占用,IO和网络是爬虫效率的最大瓶颈。在连接结构还存储在内存中的时候就完成一部分的权值计算能提升爬虫机器的运行效率。
1.严格按照robots.txt 来爬取内容,优先按照sitemap来抓取。
2.控制抓取的深度,量力而行。这个和人吃饭一次吃多少的道理是一样的。
3.网络上动态网页数量巨大,而爬虫一般是多线程的,如果爬虫对一个domain爬取的频率过高可能导致服务器无法相应;如何克服,如何让爬虫相对比较智能地平衡网络负载,运算负载,存储负载?
4.不要试图去解析页面中的脚本代码,可能是恶意的程序,也可能是有bug的代码,在本地运行会将计算的消耗提升到不可预期的程度。
5.如何节约带宽,需要检测到网页的更新,请求head信息以获取更新状态。
6.如何把计算网页权重结合到爬虫程序中?因为爬取的过程中还是相当的cpu资源没有被占用,IO和网络是爬虫效率的最大瓶颈。在连接结构还存储在内存中的时候就完成一部分的权值计算能提升爬虫机器的运行效率。
第一章 概述 Summarization of Search Engine Architecture
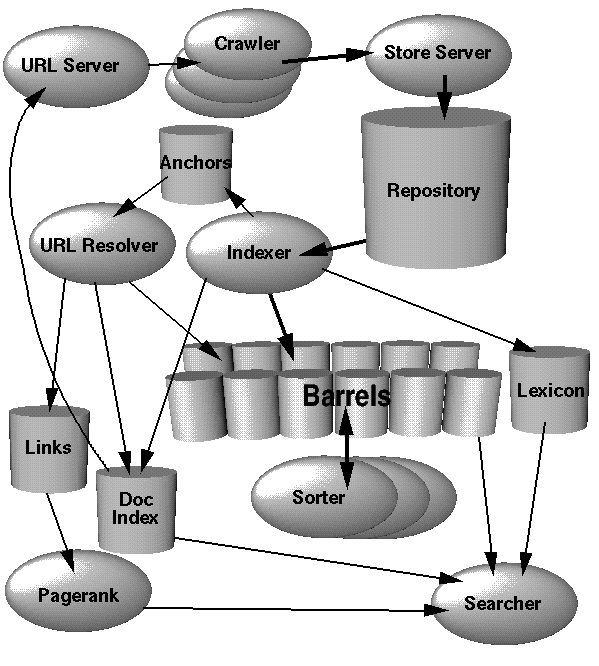
搜索引擎的架构是编写一个搜索引擎所需要考虑的第一个问题,The Anatomy of a Large-Scale Hypertextual Web Search Engine 一文对此问题做了全面的阐述。最大的功能模块可以分为:爬虫、存储、索引和web服务。爬虫负责不间断地爬取目标网站的内容,维护一张url的列表,并按照不重复的原则周期性工作;存储需要把过滤掉html tag的内容存储到本地,当然有很多内容是直接过滤的,比如js代码、影音流、图片等;然后对存储下来的内容进行批量索引,最终所有的索引内容需要合并到同一个索引中;那么有了一个建好的倒排索引,配合后台的查询语句,就可以开始web服务了,对于被检索的keyword,根据pagerank再结合内容的匹配程度,将结果呈现出来。对于用户来说,整个过程是透明的,只需要一个输入就可以得到所有可能的结果。
Tuesday, January 09, 2007
Subscribe to:
Posts (Atom)